Figures 13.6 and 13.7 #20
Labels
help wanted
Extra attention is needed
Comments
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
In Section 13.3.2, Average behavior of sequential tests, Kruschke presented simulations of outcomes based on various stopping rules (p-values, Bayes factors, and so on). From the text, we read:
He then went on to explain Figure 13.7. For the sake of space, I'll omit that prose. Here is Kruschke's Figure 13.6:
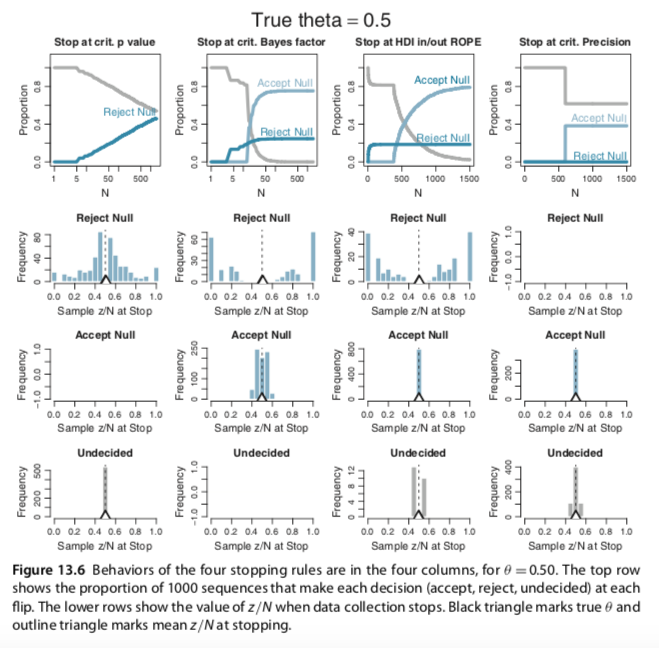
And here is Kruschke's Figure 13.7:
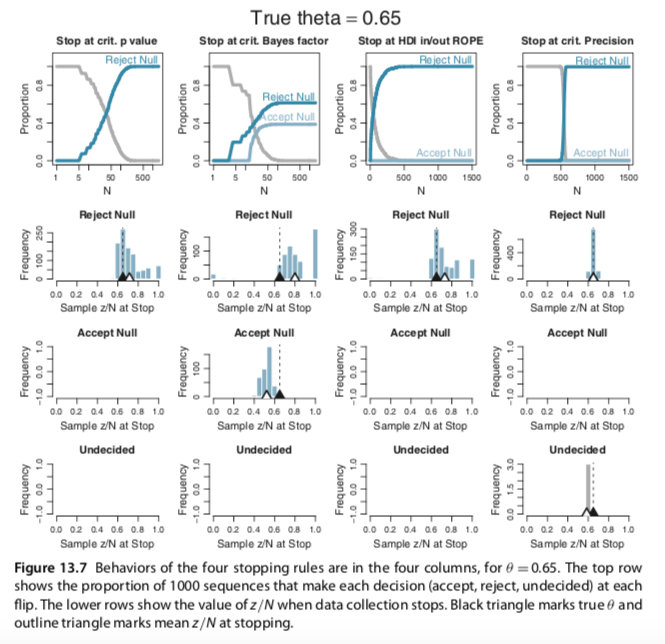
At present, I’m not sure how to pull off the simulations necessary to generate the figures. If you have the chops, please share. If at all possible tidyverse-oriented workflows are preferred.
The text was updated successfully, but these errors were encountered: