- ⚡ The Library to Build and to Auto-optimize LLM Applications ⚡
+ ⚡ The Library to Build and Auto-optimize LLM Applications ⚡
-AdalFlow helps developers build and optimize LLM task pipelines.
-Embracing similar design pattern to PyTorch, AdalFlow is light, modular, and robust, with a 100% readable codebase.
-
# Why AdalFlow?
-LLMs are like water; they can be shaped into anything, from GenAI applications such as chatbots, translation, summarization, code generation, and autonomous agents to classical NLP tasks like text classification and named entity recognition. They interact with the world beyond the model’s internal knowledge via retrievers, memory, and tools (function calls). Each use case is unique in its data, business logic, and user experience.
+Embracing a design philosophy similar to PyTorch, AdalFlow is powerful, light, modular, and robust.
+
+## Light, Modular, and Model-agnositc Task Pipeline
+
+LLMs are like water; AdalFlow help developers quickly shape them into any applications, from GenAI applications such as chatbots, translation, summarization, code generation, RAG, and autonomous agents to classical NLP tasks like text classification and named entity recognition.
+
+Only two fundamental but powerful base classes: `Component` for the pipeline and `DataClass` for data interaction with LLMs.
+The result is a library with bare minimum abstraction, providing developers with *maximum customizability*.
-Because of this, no library can provide out-of-the-box solutions. Users must build towards their own use case. This requires the library to be modular, robust, and have a clean, readable codebase. The only code you should put into production is code you either 100% trust or are 100% clear about how to customize and iterate.
+You have full control over the prompt template, the model you use, and the output parsing for your task pipeline.
+
+
+
+..
..
@@ -48,153 +77,205 @@
+.. Embracing the PyTorch-like design philosophy, AdalFlow is a powerful, light, modular, and robust library to build and auto-optimize any LLM task pipeline.
+.. AdalFlow is a powerful library to build and auto-optimize any LLM task pipeline with PyTorch-like design philosophy.
+.. # TODO: make this using the new tool, show both the building and the training.
+.. .. grid:: 1
+.. :gutter: 1
+.. .. grid-item-card:: PyTorch
-.. and Customizability
+.. .. code-block:: python
+
+.. import torch
+.. import torch.nn as nn
+
+.. class Net(nn.Module):
+.. def __init__(self):
+.. super(Net, self).__init__()
+.. self.conv1 = nn.Conv2d(1, 32, 3, 1)
+.. self.conv2 = nn.Conv2d(32, 64, 3, 1)
+.. self.dropout1 = nn.Dropout2d(0.25)
+.. self.dropout2 = nn.Dropout2d(0.5)
+.. self.fc1 = nn.Linear(9216, 128)
+.. self.fc2 = nn.Linear(128, 10)
+
+.. def forward(self, x):
+.. x = self.conv1(x)
+.. x = self.conv2(x)
+.. x = self.dropout1(x)
+.. x = self.dropout2(x)
+.. x = self.fc1(x)
+.. return self.fc2(x)
+
+.. .. grid-item-card:: AdalFlow
+
+.. .. code-block:: python
+
+.. import adalflow as adal
+.. from adalflow.components.model_client import GroqAPIClient
+
+
+.. class SimpleQA(adal.Component):
+.. def __init__(self):
+.. super().__init__()
+.. template = r"""
+.. You are a helpful assistant.
+..
+.. User: {{input_str}}
+.. You:
+.. """
+.. self.generator = adal.Generator(
+.. model_client=GroqAPIClient(),
+.. model_kwargs={"model": "llama3-8b-8192"},
+.. template=template,
+.. )
+
+.. def call(self, query):
+.. return self.generator({"input_str": query})
+
+.. async def acall(self, query):
+.. return await self.generator.acall({"input_str": query})
+.. raw:: html
+
+
+ Light, Modular, and Model-agnositc Task Pipeline
+
+
+.. Light, Modular, and Model-agnositc Task Pipeline
+.. ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+
+LLMs are like water; AdalFlow help developers quickly shape them into any applications, from GenAI applications such as chatbots, translation, summarization, code generation, RAG, and autonomous agents to classical NLP tasks like text classification and named entity recognition.
+
+
+Only two fundamental but powerful base classes: `Component` for the pipeline and `DataClass` for data interaction with LLMs.
+The result is a library with bare minimum abstraction, providing developers with *maximum customizability*.
+You have full control over the prompt template, the model you use, and the output parsing for your task pipeline.
-Light
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-AdalFlow shares similar design pattern as `PyTorch` for deep learning modeling.
-We provide developers with fundamental building blocks of *100% clarity and simplicity*.
-- Only two fundamental but powerful base classes: `Component` for the pipeline and `DataClass` for data interaction with LLMs.
-- A highly readable codebase and less than two levels of class inheritance. :doc:`tutorials/class_hierarchy`.
-- We maximize the library's tooling and prompting capabilities to minimize the reliance on LLM API features such as tools and JSON format.
-- The result is a library with bare minimum abstraction, providing developers with *maximum customizability*.
+.. figure:: /_static/images/AdalFlow_task_pipeline.png
+ :alt: AdalFlow Task Pipeline
+ :align: center
-.. grid:: 1
- :gutter: 1
- .. grid-item-card:: PyTorch
+.. raw:: html
+
+
+ Unified Framework for Auto-Optimization
+
+
+.. AdalFlow provides token-efficient and high-performing prompt optimization within a unified framework.
+.. To optimize your pipeline, simply define a ``Parameter`` and pass it to our ``Generator``.
+.. Wheter it is to optimize the task instruction or the few-shot demonstrations, our unified framework
+.. provides you easy way to ``diagnose``, ``visualize``, ``debug``, and to ``train`` your pipeline.
- .. code-block:: python
+.. This trace graph shows how our auto-diffentiation works :doc:`trace_graph <../tutorials/trace_graph>`.
- import torch
- import torch.nn as nn
+AdalFlow provides token-efficient and high-performing prompt optimization within a unified framework.
+To optimize your pipeline, simply define a ``Parameter`` and pass it to our ``Generator``.
+Whether you need to optimize task instructions or few-shot demonstrations,
+our unified framework offers an easy way to **diagnose**, **visualize**, **debug**, and **train** your pipeline.
- class Net(nn.Module):
- def __init__(self):
- super(Net, self).__init__()
- self.conv1 = nn.Conv2d(1, 32, 3, 1)
- self.conv2 = nn.Conv2d(32, 64, 3, 1)
- self.dropout1 = nn.Dropout2d(0.25)
- self.dropout2 = nn.Dropout2d(0.5)
- self.fc1 = nn.Linear(9216, 128)
- self.fc2 = nn.Linear(128, 10)
+This trace graph demonstrates how our auto-differentiation works: :doc:`trace_graph <../tutorials/trace_graph>`
- def forward(self, x):
- x = self.conv1(x)
- x = self.conv2(x)
- x = self.dropout1(x)
- x = self.dropout2(x)
- x = self.fc1(x)
- return self.fc2(x)
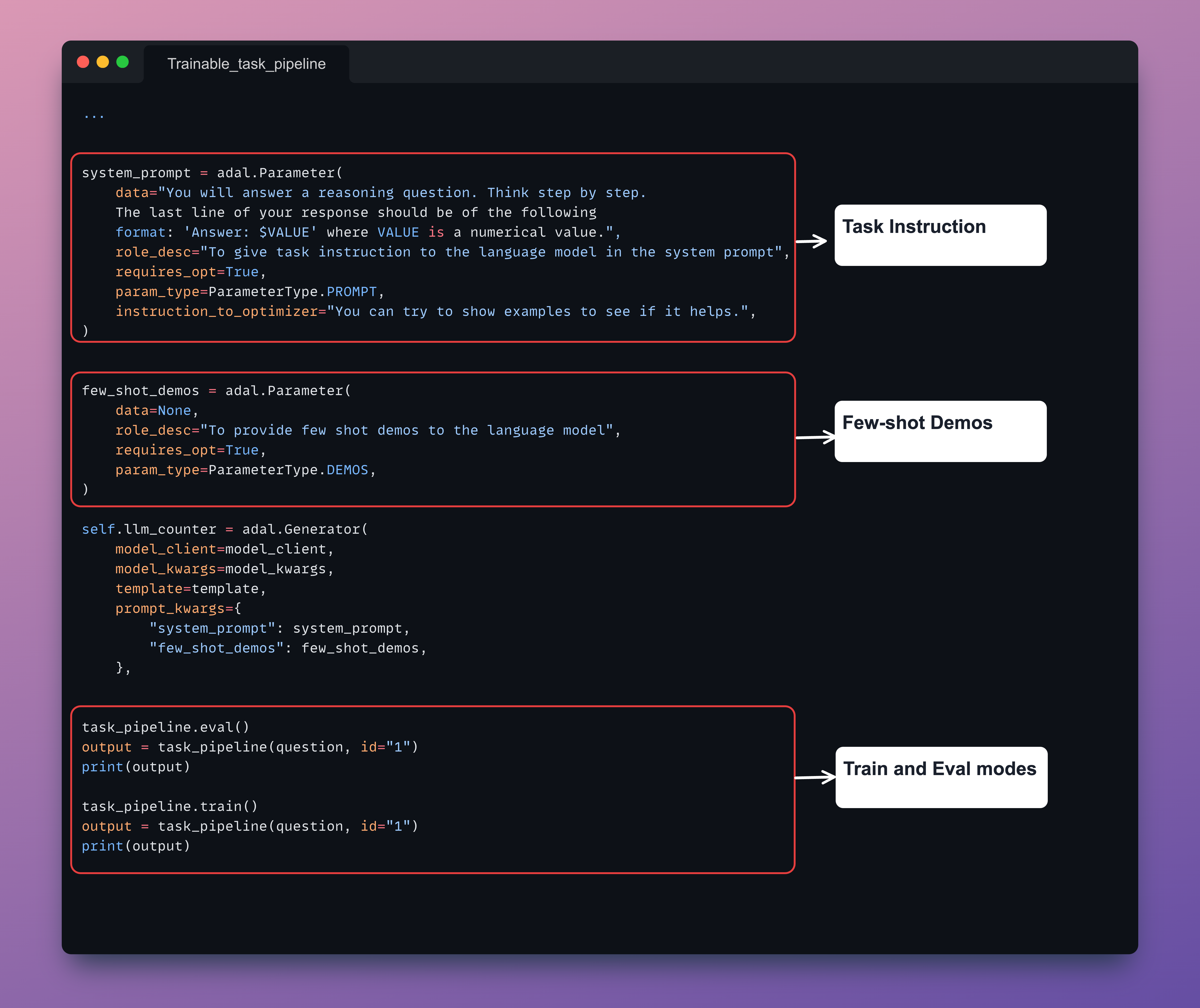
+**Trainable Task Pipeline**
- .. grid-item-card:: AdalFlow
+Just define it as a ``Parameter`` and pass it to our ``Generator``.
- .. code-block:: python
- import adalflow as adal
- from adalflow.components.model_client import GroqAPIClient
+.. figure:: /_static/images/trainable_task_pipeline.png
+ :alt: AdalFlow Trainable Task Pipeline
+ :align: center
- class SimpleQA(adal.Component):
- def __init__(self):
- super().__init__()
- template = r"""
- You are a helpful assistant.
-
- User: {{input_str}}
- You:
- """
- self.generator = adal.Generator(
- model_client=GroqAPIClient(),
- model_kwargs={"model": "llama3-8b-8192"},
- template=template,
- )
- def call(self, query):
- return self.generator({"input_str": query})
+``AdalComponent`` acts as the `interpreter` between task pipeline and the trainer, defining training and validation steps, optimizers, evaluators, loss functions, backward engine for textual gradients or tracing the demonstrations, the teacher generator.
- async def acall(self, query):
- return await self.generator.acall({"input_str": query})
+**AdalComponent & Trainer**
-.. - We use 10X less code than other libraries to achieve 10X more robustness and flexibility.
+.. figure:: /_static/images/trainer.png
+ :alt: AdalFlow AdalComponent & Trainer
+ :align: center
-.. Each developer has unique data needs to build their own models/components, experiment with In-context Learning (ICL) or model finetuning, and deploy the LLM applications to production. This means the library must provide fundamental lower-level building blocks and strive for clarity and simplicity:
+.. and Customizability
+
+
+.. Light
+.. ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+.. AdalFlow shares similar design pattern as `PyTorch` for deep learning modeling.
+.. We provide developers with fundamental building blocks of *100% clarity and simplicity*.
+.. - Only two fundamental but powerful base classes: `Component` for the pipeline and `DataClass` for data interaction with LLMs.
+.. - A highly readable codebase and less than two levels of class inheritance. :doc:`tutorials/class_hierarchy`.
+.. - We maximize the library's tooling and prompting capabilities to minimize the reliance on LLM API features such as tools and JSON format.
+.. - The result is a library with bare minimum abstraction, providing developers with *maximum customizability*.
-Modular
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-AdalFlow resembles PyTorch in the way that we provide a modular and composable structure for developers to build and to optimize their LLM applications.
-- `Component` and `DataClass` are to AdalFlow for LLM Applications what `module` and `Tensor` are to PyTorch for deep learning modeling.
-- `ModelClient` to bridge the gap between the LLM API and the AdalFlow pipeline.
-- `Orchestrator` components like `Retriever`, `Embedder`, `Generator`, and `Agent` are all model-agnostic (you can use the component on different models from different providers).
+.. Modular
+.. ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+.. AdalFlow resembles PyTorch in the way that we provide a modular and composable structure for developers to build and to optimize their LLM applications.
-Similar to the PyTorch `module`, our `Component` provides excellent visualization of the pipeline structure.
+.. - `Component` and `DataClass` are to AdalFlow for LLM Applications what `module` and `Tensor` are to PyTorch for deep learning modeling.
+.. - `ModelClient` to bridge the gap between the LLM API and the AdalFlow pipeline.
+.. - `Orchestrator` components like `Retriever`, `Embedder`, `Generator`, and `Agent` are all model-agnostic (you can use the component on different models from different providers).
-.. code-block::
- SimpleQA(
- (generator): Generator(
- model_kwargs={'model': 'llama3-8b-8192'},
- (prompt): Prompt(
- template:
- You are a helpful assistant.
-
- User: {{input_str}}
- You:
- , prompt_variables: ['input_str']
- )
- (model_client): GroqAPIClient()
- )
- )
+.. Similar to the PyTorch `module`, our `Component` provides excellent visualization of the pipeline structure.
-To switch to `gpt-3.5-turbo` by OpenAI, simply update the `model_client`` and `model_kwargs` in the Generator component.
+.. .. code-block::
-.. code-block:: python
+.. SimpleQA(
+.. (generator): Generator(
+.. model_kwargs={'model': 'llama3-8b-8192'},
+.. (prompt): Prompt(
+.. template:
+.. You are a helpful assistant.
+..
+.. User: {{input_str}}
+.. You:
+.. , prompt_variables: ['input_str']
+.. )
+.. (model_client): GroqAPIClient()
+.. )
+.. )
- from adalflow.components.model_client import OpenAIClient
+.. To switch to `gpt-3.5-turbo` by OpenAI, simply update the `model_client`` and `model_kwargs` in the Generator component.
- self.generator = adal.Generator(
- model_client=OpenAIClient(),
- model_kwargs={"model": "gpt-3.5-turbo"},
- template=template,
- )
+.. .. code-block:: python
+.. from adalflow.components.model_client import OpenAIClient
-.. and Robustness
+.. self.generator = adal.Generator(
+.. model_client=OpenAIClient(),
+.. model_kwargs={"model": "gpt-3.5-turbo"},
+.. template=template,
+.. )
-Robust
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-Our simplicity did not come from doing less.
-On the contrary, we have to do more and go deeper and wider on any topic to offer developers *maximum control and robustness*.
-- LLMs are sensitive to the prompt. We allow developers full control over their prompts without relying on LLM API features such as tools and JSON format with components like `Prompt`, `OutputParser`, `FunctionTool`, and `ToolManager`.
-- Our goal is not to optimize for integration, but to provide a robust abstraction with representative examples. See this in :ref:`ModelClient
` and :ref:`Retriever` components.
-- All integrations, such as different API SDKs, are formed as optional packages but all within the same library. You can easily switch to any models from different providers that we officially support.
+.. Robust
+.. ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+.. Our simplicity did not come from doing less.
+.. On the contrary, we have to do more and go deeper and wider on any topic to offer developers *maximum control and robustness*.
+.. - LLMs are sensitive to the prompt. We allow developers full control over their prompts without relying on LLM API features such as tools and JSON format with components like `Prompt`, `OutputParser`, `FunctionTool`, and `ToolManager`.
+.. - Our goal is not to optimize for integration, but to provide a robust abstraction with representative examples. See this in :ref:`ModelClient` and :ref:`Retriever` components.
+.. - All integrations, such as different API SDKs, are formed as optional packages but all within the same library. You can easily switch to any models from different providers that we officially support.
-.. Coming from a deep AI research background, we understand that the more control and transparency developers have over their prompts, the better. In default:
-.. - AdalFlow simplifies what developers need to send to LLM proprietary APIs to just two messages each time: a `system message` and a `user message`. This minimizes reliance on and manipulation by API providers.
-.. - AdalFlow provides advanced tooling for developers to build `agents`, `tools/function calls`, etc., without relying on any proprietary API provider's 'advanced' features such as `OpenAI` assistant, tools, and JSON format
-.. It is the future of LLM applications
Unites Research and Production
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
diff --git a/docs/source/tutorials/index.rst b/docs/source/tutorials/index.rst
index 8fa9027b..f3cca718 100644
--- a/docs/source/tutorials/index.rst
+++ b/docs/source/tutorials/index.rst
@@ -41,6 +41,7 @@ We have a clear :doc:`lightrag_design_philosophy`, which results in this :doc:`c
lightrag_design_philosophy
class_hierarchy
+ trace_graph
Introduction
diff --git a/docs/source/use_cases/question_answering.rst b/docs/source/use_cases/question_answering.rst
index 78d591bf..fe7e7b82 100644
--- a/docs/source/use_cases/question_answering.rst
+++ b/docs/source/use_cases/question_answering.rst
@@ -754,3 +754,10 @@ We also leverage single message prompt, sending the whole template to the model'
.. note::
In the start we use same prompt but we use a single template which achieves much better zero-shot performance than text-grad which sends the system prompt to system message and the input to user message.
+
+.. admonition:: References
+ :class: highlight
+
+ .. [1] Text-grad: https://arxiv.org/abs/2406.07496
+ .. [2] DsPy: https://arxiv.org/abs/2310.03714
+ .. [3] ORPO: https://arxiv.org/abs/2309.03409
diff --git a/tutorials/task_pipeline.py b/tutorials/task_pipeline.py
new file mode 100644
index 00000000..f0502356
--- /dev/null
+++ b/tutorials/task_pipeline.py
@@ -0,0 +1,168 @@
+from typing import Dict, Union, Optional
+import re
+from dataclasses import dataclass, field
+
+
+import adalflow as adal
+from adalflow.optim.types import ParameterType
+
+template = r"""
+You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.
+
+
+{{input_str}}
+
+"""
+
+
+@adal.fun_to_component
+def parse_integer_answer(answer: str):
+ """A function that parses the last integer from a string using regular expressions."""
+ try:
+ numbers = re.findall(r"\d+", answer)
+ if numbers:
+ answer = int(numbers[-1])
+ else:
+ answer = -1
+ except ValueError:
+ answer = -1
+ return answer
+
+
+class ObjectCountTaskPipeline(adal.Component):
+ def __init__(self, model_client: adal.ModelClient, model_kwargs: Dict):
+ super().__init__()
+
+ self.llm_counter = adal.Generator(
+ model_client=model_client,
+ model_kwargs=model_kwargs,
+ template=template,
+ output_processors=parse_integer_answer,
+ )
+
+ def call(self, question: str, id: str = None) -> adal.GeneratorOutput:
+ output = self.llm_counter(prompt_kwargs={"input_str": question}, id=id)
+ return output
+
+
+template = r"""
+You will answer a reasoning question. Think step by step.
+{{output_format_str}}
+{% if few_shot_demos is not none %}
+Here are some examples:
+{{few_shot_demos}}
+{% endif %}
+
+
+{{input_str}}
+
+"""
+
+
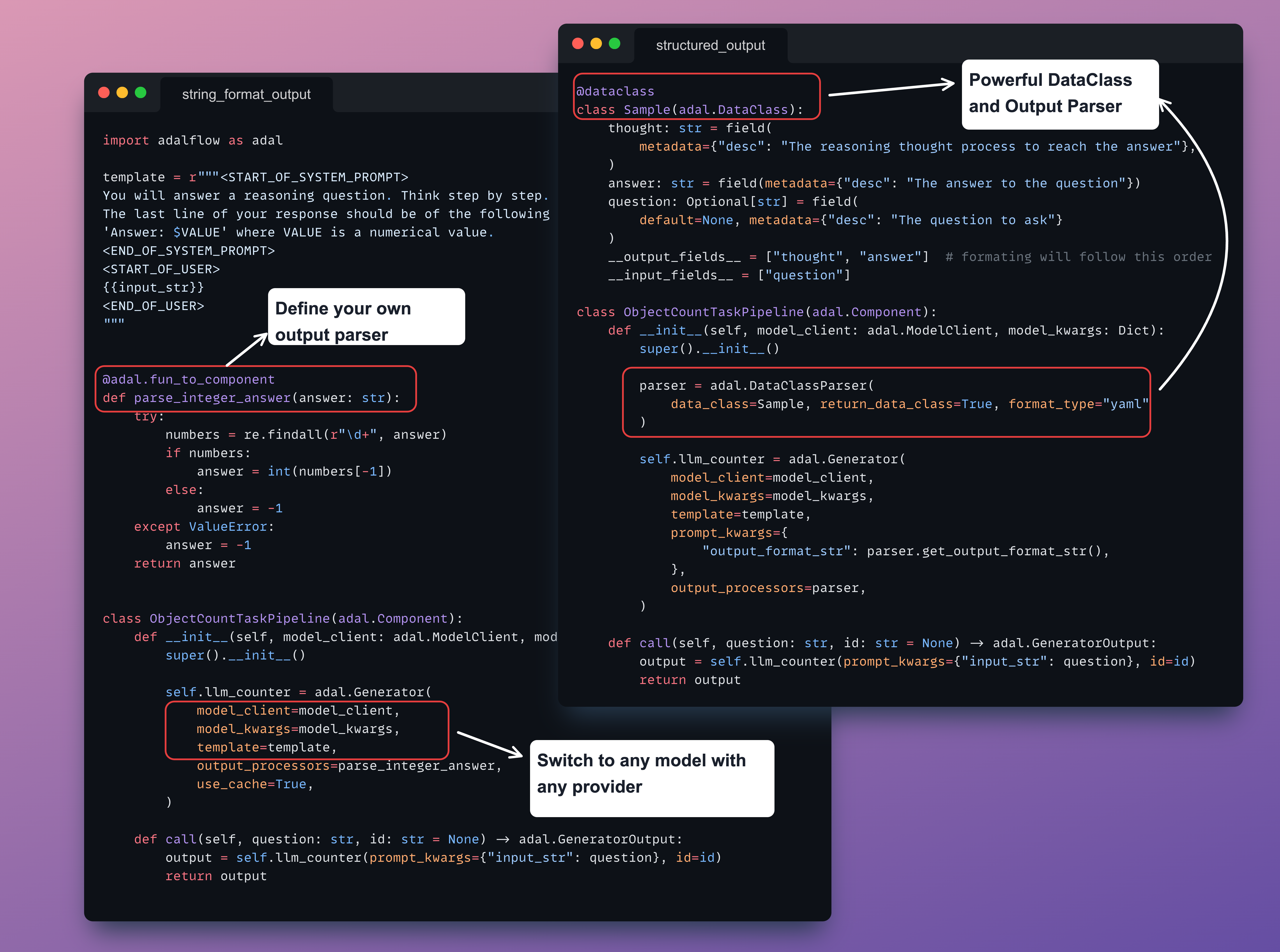
+@dataclass
+class Sample(adal.DataClass):
+ thought: str = field(
+ metadata={"desc": "The reasoning thought process to reach the answer"},
+ )
+ answer: str = field(metadata={"desc": "The answer to the question"})
+ question: Optional[str] = field(
+ default=None, metadata={"desc": "The question to ask"}
+ )
+ __output_fields__ = ["thought", "answer"] # formating will follow this order
+ __input_fields__ = ["question"]
+
+
+class ObjectCountTaskStrucutredPipeline(adal.Component):
+ def __init__(self, model_client: adal.ModelClient, model_kwargs: Dict):
+ super().__init__()
+
+ parser = adal.DataClassParser(
+ data_class=Sample, return_data_class=True, format_type="yaml"
+ )
+ self.llm_counter = adal.Generator(
+ model_client=model_client,
+ model_kwargs=model_kwargs,
+ template=template,
+ prompt_kwargs={
+ "output_format_str": parser.get_output_format_str(),
+ },
+ output_processors=parser,
+ )
+
+ def call(self, question: str, id: str = None) -> adal.GeneratorOutput:
+ output = self.llm_counter(prompt_kwargs={"input_str": question}, id=id)
+ return output
+
+
+few_shot_template = r"""
+{{system_prompt}}
+{# Few shot demos #}
+{% if few_shot_demos is not none %}
+Here are some examples:
+{{few_shot_demos}}
+{% endif %}
+
+
+{{input_str}}
+
+"""
+
+
+class ObjectCountTaskPipelineTrainable(adal.Component):
+ def __init__(self, model_client: adal.ModelClient, model_kwargs: Dict):
+ super().__init__()
+
+ system_prompt = adal.Parameter(
+ data="You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.",
+ role_desc="To give task instruction to the language model in the system prompt",
+ requires_opt=False,
+ param_type=ParameterType.PROMPT,
+ instruction_to_optimizer="You can try to show examples to see if it helps.",
+ )
+ few_shot_demos = adal.Parameter(
+ data=None,
+ role_desc="To provide few shot demos to the language model",
+ requires_opt=True,
+ param_type=ParameterType.DEMOS,
+ )
+
+ self.llm_counter = adal.Generator(
+ model_client=model_client,
+ model_kwargs=model_kwargs,
+ template=template,
+ prompt_kwargs={
+ "system_prompt": system_prompt,
+ "few_shot_demos": few_shot_demos,
+ },
+ output_processors=parse_integer_answer,
+ use_cache=True,
+ )
+
+ def call(
+ self, question: str, id: str = None
+ ) -> Union[adal.GeneratorOutput, adal.Parameter]:
+ output = self.llm_counter(prompt_kwargs={"input_str": question}, id=id)
+ return output
+
+
+if __name__ == "__main__":
+ model_client = adal.ModelClient(model_name="gpt2")
+ model_kwargs = {"temperature": 0.7}
+
+ from adalflow.utils import setup_env
+ from adalflow.components.model_client import OpenAIClient
+
+ setup_env()
+
+ task_pipeline = ObjectCountTaskPipelineTrainable(
+ model_client=OpenAIClient(), model_kwargs={"model": "gpt-3.5-turbo"}
+ )
+ question = "I have a flute, a piano, a trombone, four stoves, a violin, an accordion, a clarinet, a drum, two lamps, and a trumpet. How many musical instruments do I have?"
+
+ task_pipeline.eval()
+ output = task_pipeline(question, id="1")
+ print(output)
+
+ task_pipeline.train()
+ output = task_pipeline(question, id="1")
+ print(output)
diff --git a/use_cases/question_answering/bhh_object_count/train_new.py b/use_cases/question_answering/bhh_object_count/train_new.py
index 34a3c4c0..abf0d901 100644
--- a/use_cases/question_answering/bhh_object_count/train_new.py
+++ b/use_cases/question_answering/bhh_object_count/train_new.py
@@ -1,5 +1,3 @@
-from adalflow.optim.trainer.trainer import Trainer
-
from use_cases.question_answering.bhh_object_count.task import (
ObjectCountTaskPipeline,
)
@@ -129,7 +127,7 @@ def train(
backward_engine_model_config=gpt_4o_model
)
print(adal_component)
- trainer = Trainer(
+ trainer = adal.Trainer(
train_batch_size=train_batch_size,
strategy=strategy,
max_steps=max_steps,
 +
+ +
+ +
+

