我们是用开源版本的stable-diffusion-3-medium-diffusers 2B模型进行性能评测。
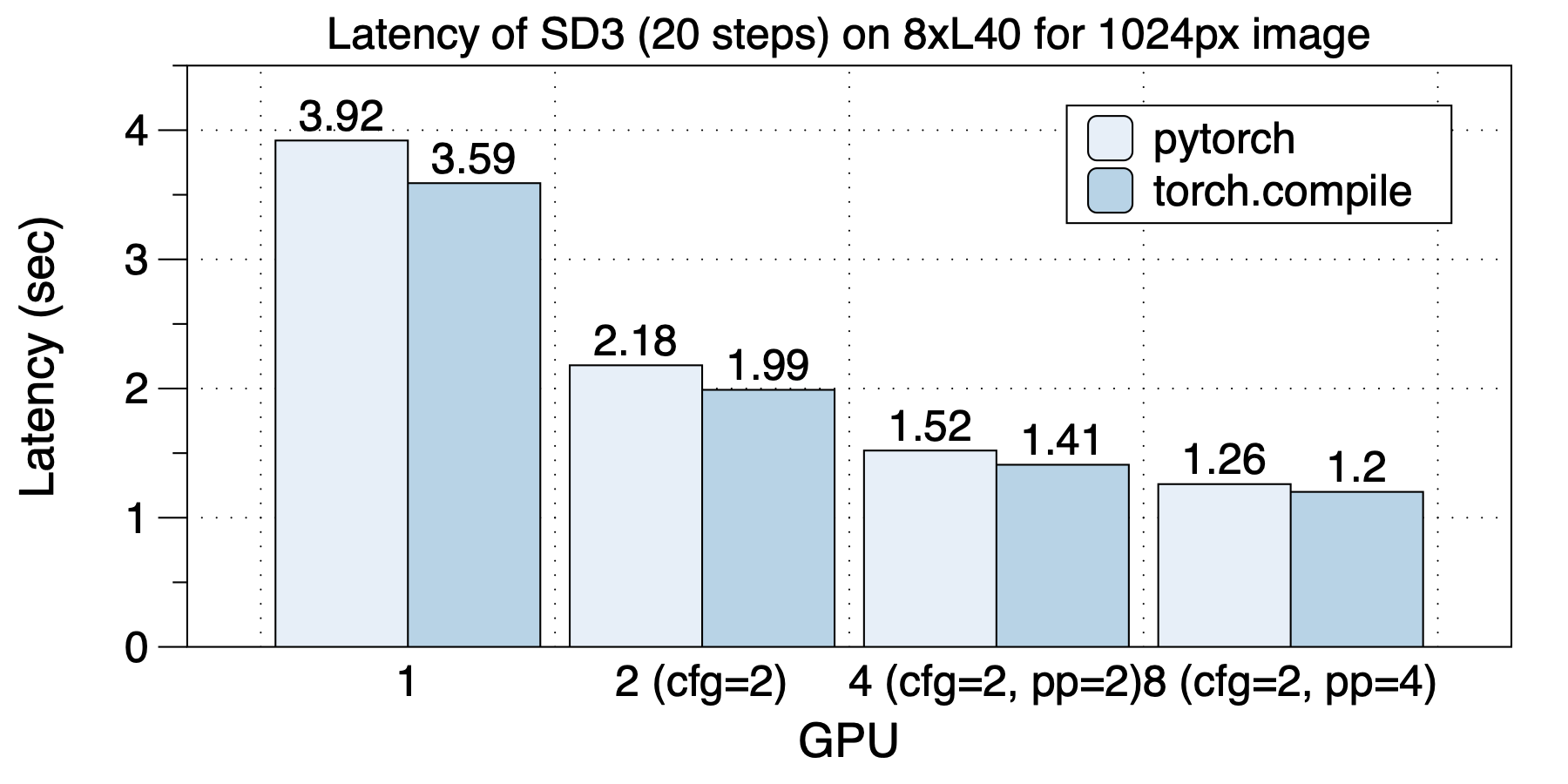
在8xA100(NVLink)机器上,在使用不同GPU数目时,最佳的并行方案都是不同的。这说明了多种并行和混合并行的重要性。
最佳的并行策略在不同GPU规模时分别是:在2个GPU上,使用cfg_parallel=2;在4个GPU上,使用cfg_parallel=2, pipefusion_parallel=2;在8个GPU上,使用cfg_parallel=2, pipefusion_parallel=4。
torch.compile在除了8 GPU的场景下都来来了加速效果。
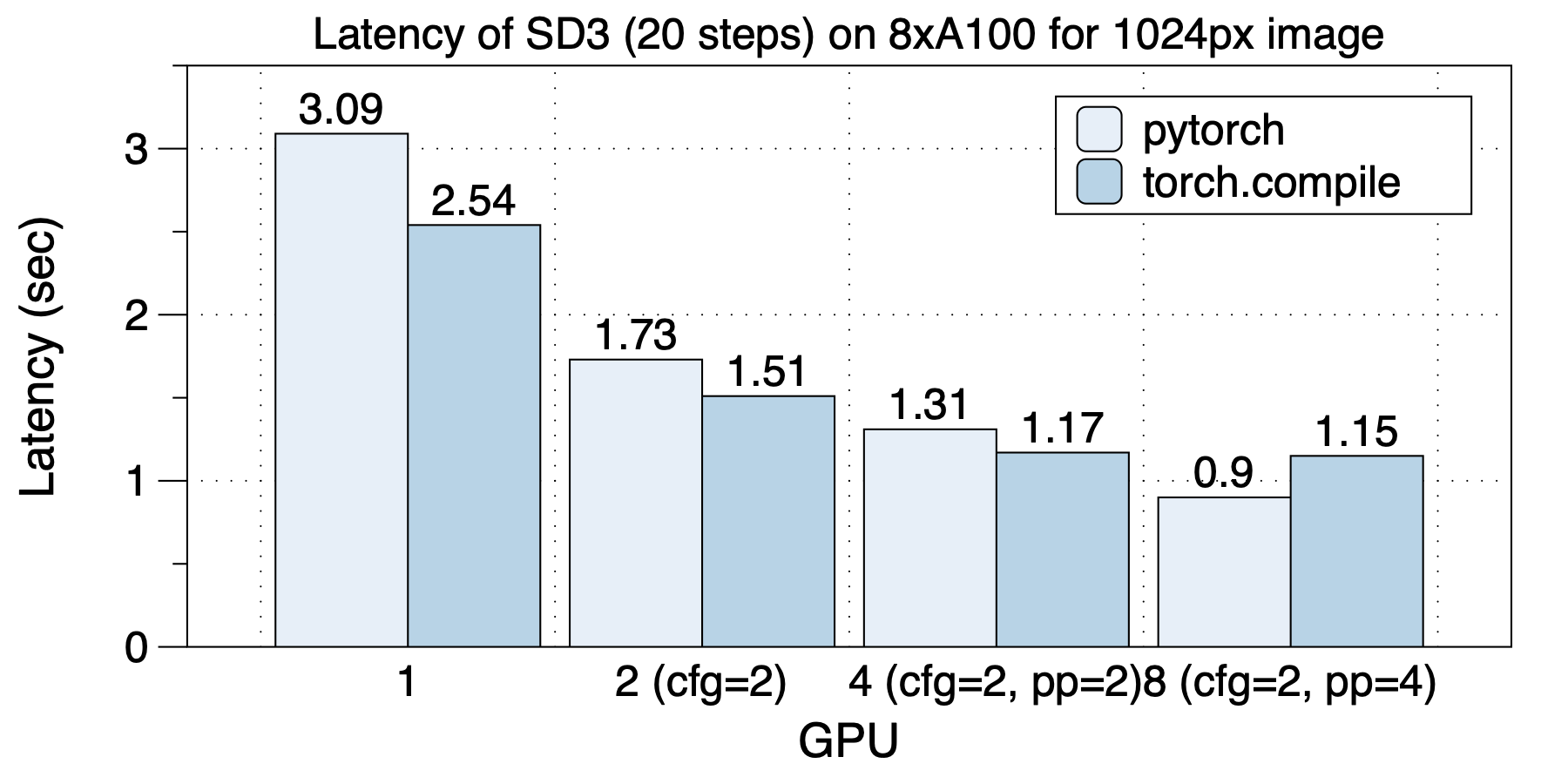
在8xL40 (PCIe)上的延迟情况如下图所示。同样,不同GPU规模,最佳并行策略都是不同的。 torch.compile都来了加速效果。