Persisting Data
With new COVID-19 data coming in on a daily basis we need to have pipelines to join and stash the relevant data sources. We want to enable data to be easily tracked and versioned to make models reproducible.
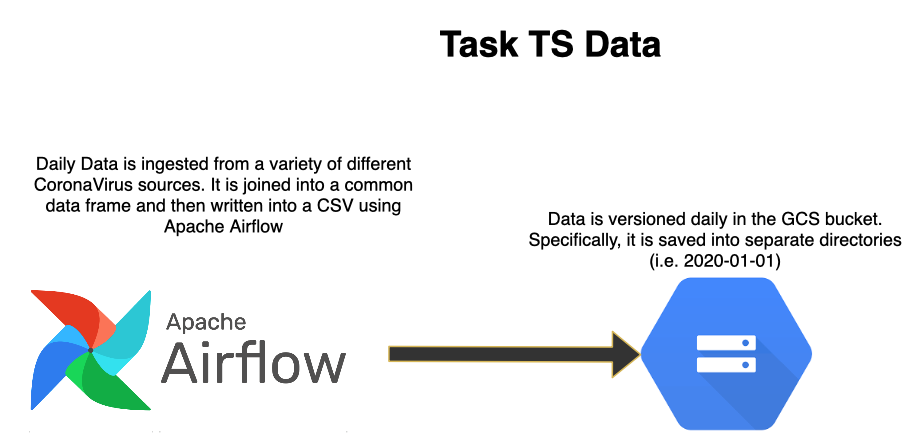
Airflow
Airflow will be used to schedule daily jobs to persist data to GCS and Dataverse.
GCS Layout
GCS will be organized into directories based on the date. For example COVID files will be stashed
06-10-2020/raw_data.csv This enables restoring data in case our data sources change.
Big Query
Enabling easy access to the COVID-19 data for both training models and analysis by epidemiologists is crucial. For this purpose Google Big Query will be utilized. We plan on stashing all of our data in easy to query tables.