

The following Notebook was created in order to classify images into two categories: Food, and Non-Food. It relies on Keras, a high-level neural networks API.
The following implementation compares the performance of a Convolutional Neural Network with the following parameters:
- Number of layers: 1, 2, 3
- Learning rate: 1e-3
- Batch Size: 32, 100
- Epochs: 20
- Image Size: 32x32px, 64x64px
- Number of kernels in a layer: 10, 20 in the first layer; 50, 100 in the second layer
- Kernel size: 5x5 small image; 7x7 large image
Each layer follows CONV -> RELU -> MAXPOOL
The datasets is split three-way: Training: 60% Test: 20% Validation: 20%
Images used in the training/testing/validation are a mix of publicly available datasets.
The dataset has been preprocessed by resizing the images into 32x32 and 64x64px. The images remain as RGB, not gray-scale. The argument for keeping the representation as RGB is supported by Kiyoharu Aizawa, in the paper "Food Detection and Recognition Using Convolutional Neural Network," and can be found here.
Since the dataset used in training is sizable (~5.2k Food, ~4.5k Non-Food), there is no need for augumentation. However, on a limited dataset it would be beneficial to apply augumentation with Keras ImageDataGenerator, using the following techniques:
- rotation
- width/height shift
- sheer range
- zoom range
- horizontal flip
Layer Size: 20 neurons Neuron Size: 5x5 Batch Size: 32
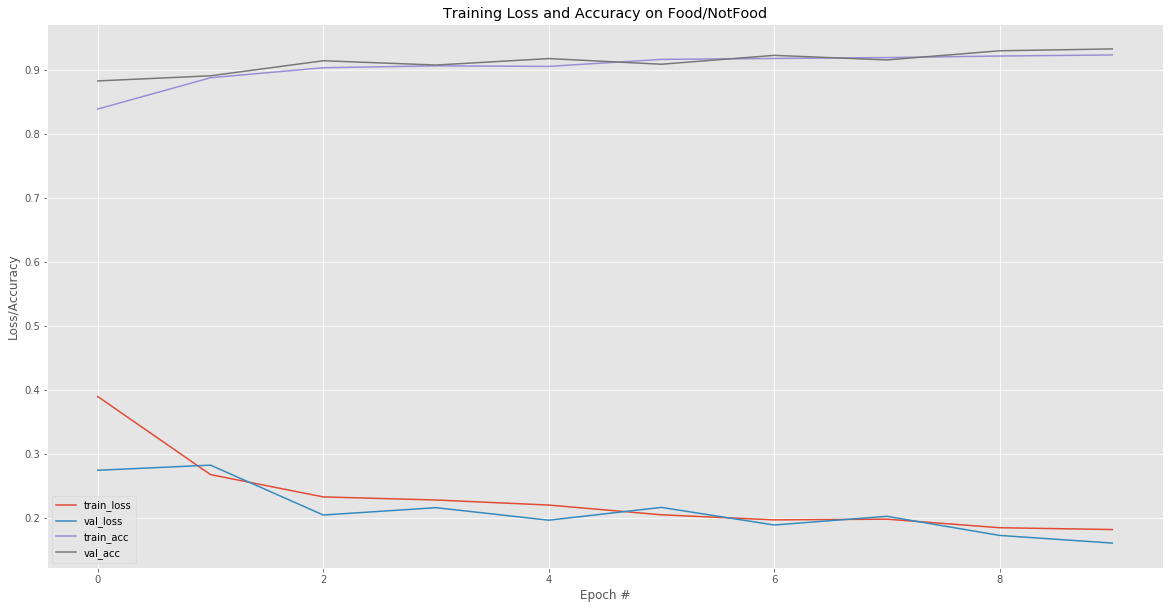
Layer One Size: 20 neurons
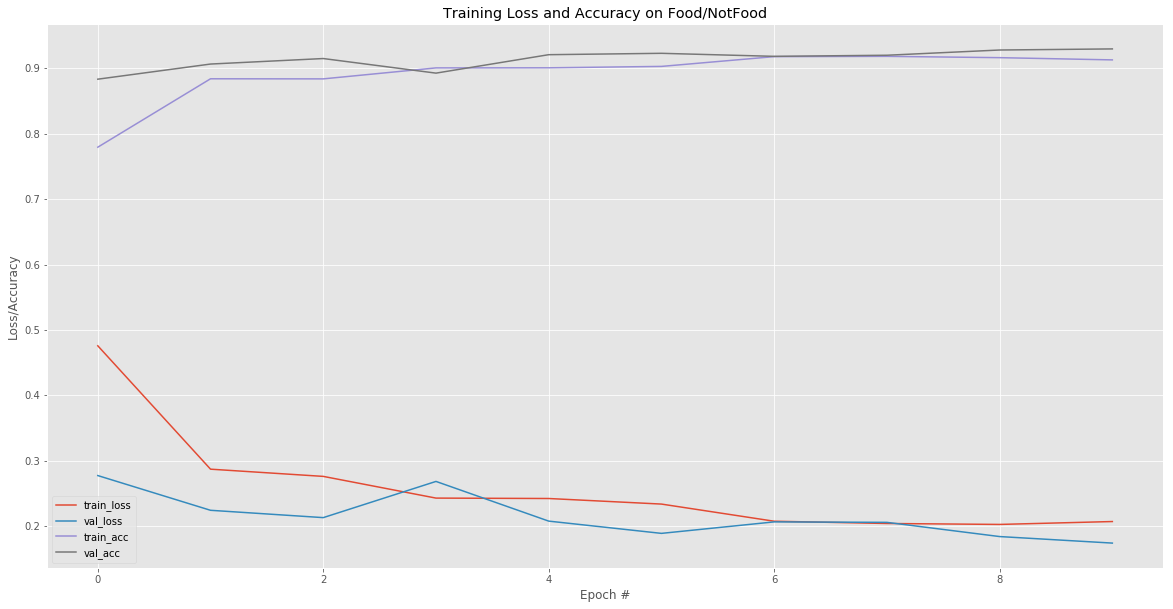
Layer Two Size: 100 neurons
Neuron Size: 7x7
Batch Size: 100
$ python classifier -m model.h5 -i path_to_image.jpg