Releases: jparkerweb/semantic-chunking
v2.4.1 - ✂️ Clean Split
What's New 🎉
2.4.1
📦 Updated
- Updated sentence splitter to use
@stdlib/nlp-sentencize - Updated embedding cache to use
lru-cache
v2.4.0
✨ Added
sentenceitfunction (split by sentence and return embeddings)
Please consider sending me a tip to support my work 😀
🍵 tip me here
⇢ 💻 Visit eQuill Labs
⇢ 💬 Join the Discord
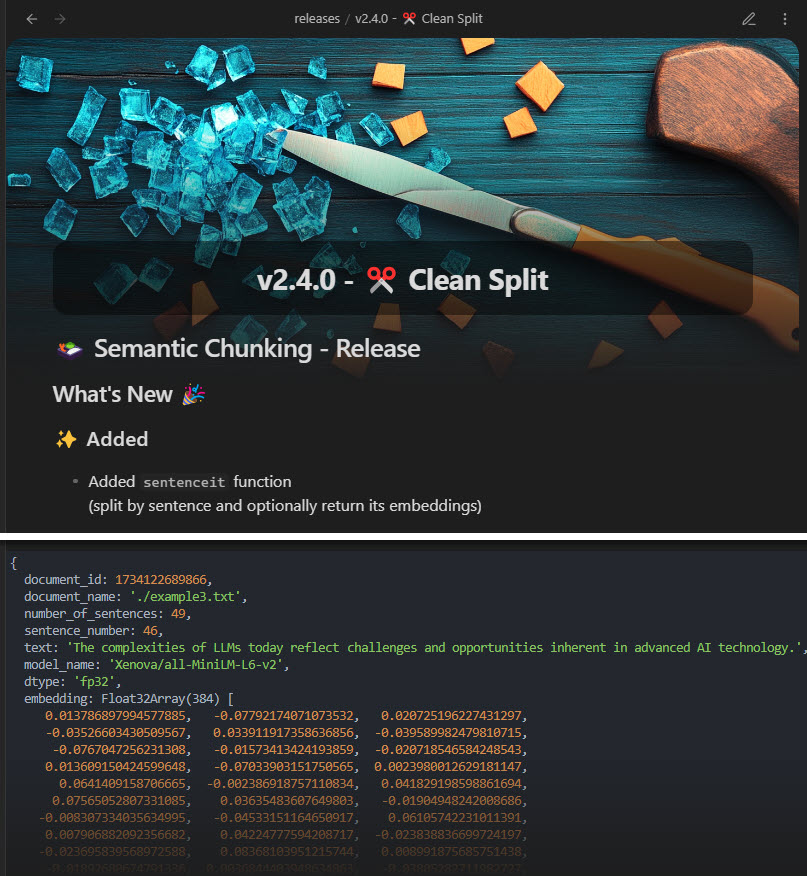
v2.4.0 - ✂️ Clean Split
What's New 🎉
v2.4.0
✨ Added
sentenceitfunction (split by sentence and return embeddings)
Please consider sending me a tip to support my work 😀
🍵 tip me here
⇢ 💻 Visit eQuill Labs
⇢ 💬 Join the Discord
v2.3.7 - 📦 Transformers.js v3
[2.3.1] - [2.3.7] 2024-11-25
Updated
- Updated Web UI to v1.3.1
- Updated Documentation
- Updated default values in both the library and Web UI
- Web UI default can be set in
webui/public/default-form-values.js
- Web UI default can be set in
- Only print version if logging is enabled (default is false)
- was adding console noise to upstream applications
- Update
string-segmenterpatch version dependency - Misc cleanup and optimizations
[2.3.0] - 2024-11-11
Updated
- Updated
transformers.jsfrom v2 to v3 - Migrated quantization option from
onnxEmbeddingModelQuantized(boolean) todtype('p32', 'p16', 'q8', 'q4') - Updated Web UI to use new
dtypeoption

If you enjoy this package please consider sending me a tip to support my work 😀
🍵 tip me here
v2.3.4 - 📦 Transformers.js v3
[2.3.1] - [2.3.4] 2024-11-12
Updated
- Updated Web UI to v1.3.1
- Updated Documentation
- Updated default values in both the library and Web UI
- Web UI default can be set in
webui/public/default-form-values.js
- Web UI default can be set in
- Misc cleanup and optimizations
[2.3.0] - 2024-11-11
Updated
- Updated
transformers.jsfrom v2 to v3 - Migrated quantization option from
onnxEmbeddingModelQuantized(boolean) todtype('p32', 'p16', 'q8', 'q4') - Updated Web UI to use new
dtypeoption
If you enjoy this package please consider sending me a tip to support my work 😀
🍵 tip me here
v2.2.4 - 🎯 Web UI for Tuning
[2.2.4] - 2024-11-08
Fixed
- Fixed issue with Web UI embedding cache not being cleared when a new model is initialized.
[2.2.3] - 2024-11-07
Added
- Web UI adjustments for display of truncated JSON results on screen but still allowing download of full results.
[2.2.2] - 2024-11-07
Added
- Web UI css adjustments for smaller screens
[2.2.1] - 2024-11-06
Added
- Added Highlight.js to Web UI for syntax highlighting of JSON results and code samples
- Added JSON results toggle button to turn line wrapping on/off
[2.2.0] - 2024-11-05
Added
- New Web UI tool for experimenting with semantic chunking settings
- Interactive form interface for all chunking parameters
- Real-time text processing and results display
- Visual feedback for similarity thresholds
- Model selection and configuration
- Results download in JSON format
- Code generation for settings
- Example texts for testing
- Dark mode interface
- Added
excludeChunkPrefixInResultsoption tochunkitandcramitfunctions- Allows removal of chunk prefix from final results while maintaining prefix for embedding calculations
Updated
- Improved error handling and feedback in chunking functions
- Enhanced documentation with Web UI usage examples
- Added more embedding models to supported list
Fixed
- Fixed issue with chunk prefix handling in embedding calculations
- Improved token length calculation reliability

If you enjoy this package please consider sending me a tip to support my work 😀
🍵 tip me here
v2.2.0 - 🎯 Web UI for Tuning
[2.2.0] - 2024-11-05
Added
- New Web UI tool for experimenting with semantic chunking settings
- Interactive form interface for all chunking parameters
- Real-time text processing and results display
- Visual feedback for similarity thresholds
- Model selection and configuration
- Results download in JSON format
- Code generation for settings
- Example texts for testing
- Dark mode interface
- Added
excludeChunkPrefixInResultsoption tochunkitandcramitfunctions- Allows removal of chunk prefix from final results while maintaining prefix for embedding calculations
If you enjoy this package please consider sending me a tip to support my work 😀
🍵 tip me here
v2.1.4 - 💎 Rich Output
🎉 What's New
[2.1.4] - 2024-11-04
Updated
- Updated README
cramitexample script to use updated document object input format.
[2.1.3] - 2024-11-04
Fixed
- Fixed
cramitfunction to properly pack sentences up to maxTokenSize
Updated
- Improved chunk creation logic to better handle both chunkit and cramit modes
- Enhanced token size calculation efficiency
[2.1.2] - 2024-11-04
Fixed
- Improved semantic chunking accuracy with stricter similarity thresholds
- Enhanced logging in similarity calculations for better debugging
- Fixed chunk creation to better respect semantic boundaries
Updated
- Default similarity threshold increased to 0.5
- Default dynamic threshold bounds adjusted (0.4 - 0.8)
- Improved chunk rebalancing logic with similarity checks
- Updated logging for similarity scores between sentences
[2.1.1] - 2024-11-01
Updated
- Updated example scripts in README.
[2.1.0] - 2024-11-01
Updated
⚠️ BREAKING: Input format now accepts array of document objects- Output array of chunks extended with the following new properties:
document_id: Timestamp in milliseconds when processing starteddocument_name: Original document name or ""number_of_chunks: Total number of chunks for the documentchunk_number: Current chunk number (1-based)model_name: Name of the embedding model usedis_model_quantized: Whether the model is quantized
[2.0.0] - 2024-11-01
Added
- Added
returnEmbeddingoption tochunkitandcramitfunctions to include embeddings in the output. - Added
returnTokenLengthoption tochunkitandcramitfunctions to include token length in the output. - Added
chunkPrefixoption to prefix each chunk with a task instruction (e.g., "search_document: ", "search_query: "). - Updated README to document new options and add RAG tips for using
chunkPrefixwith embedding models that support task prefixes.
Updated
⚠️ BREAKING: Returned array of chunks is now an array of objects withtext,embedding, andtokenLengthproperties. Previous versions returned an array of strings.
If you find this library useful please consider sending me a tip to support my work 😀
🍵 tip me here
v2.1.0 - 💎 Rich Output
🎉 What's New
[2.1.0] - 2024-11-01
Updated
⚠️ BREAKING: Input format now accepts array of document objects- Output array of chunks extended with the following new properties:
document_id: Timestamp in milliseconds when processing starteddocument_name: Original document name or ""number_of_chunks: Total number of chunks for the documentchunk_number: Current chunk number (1-based)model_name: Name of the embedding model usedis_model_quantized: Whether the model is quantized
If you find this library useful please consider sending me a tip to support my work 😀
🍵 tip me here
v2.0.0 - 🔍 Embeddings, Tokens and Prefixes Oh My!
🎉 What's New
Added
- Added
returnEmbeddingoption tochunkitandcramitfunctions to include embeddings in the output. - Added
returnTokenLengthoption tochunkitandcramitfunctions to include token length in the output. - Added
chunkPrefixoption to prefix each chunk with a task instruction (e.g., "search_document: ", "search_query: "). - Updated README to document new options and add RAG tips for using
chunkPrefixwith embedding models that support task prefixes.
⚠️ Breaking Change
- Returned array chunks is now an array of objects with
text,embedding, andtokenLengthproperties. Previous versions returned an array of strings.
If you find this library useful please consider sending me a tip to support my work 😀
🍵 tip me here
v1.4.0
What's Changed
- breakup main chunkit file into modules by @jparkerweb in #6
Full Changelog: 1.3.0...1.4.0
If you enjoy this plugin please consider sending me a tip to support my work 😀
🍵 tip me here